Vocabulary Learning via Optimal Transport for Neural Machine Translation
VOLT is a research work exploring how to generate the optimal vocabulary for neural machine translation. In recent days, this paper got a lot of attentions and we also received several questions from readers. To help more readers understand our work better, I write this blog. In this blog, I will try my best to explain the formulations and motivations behind VOLT. I will use easy-to-understand examples for illustration (maybe not very rigorous for paper writing but somehow ok for blogs). If you have more questions, please feel free to contact us. You can find our e-mails on the published paper.
Outline
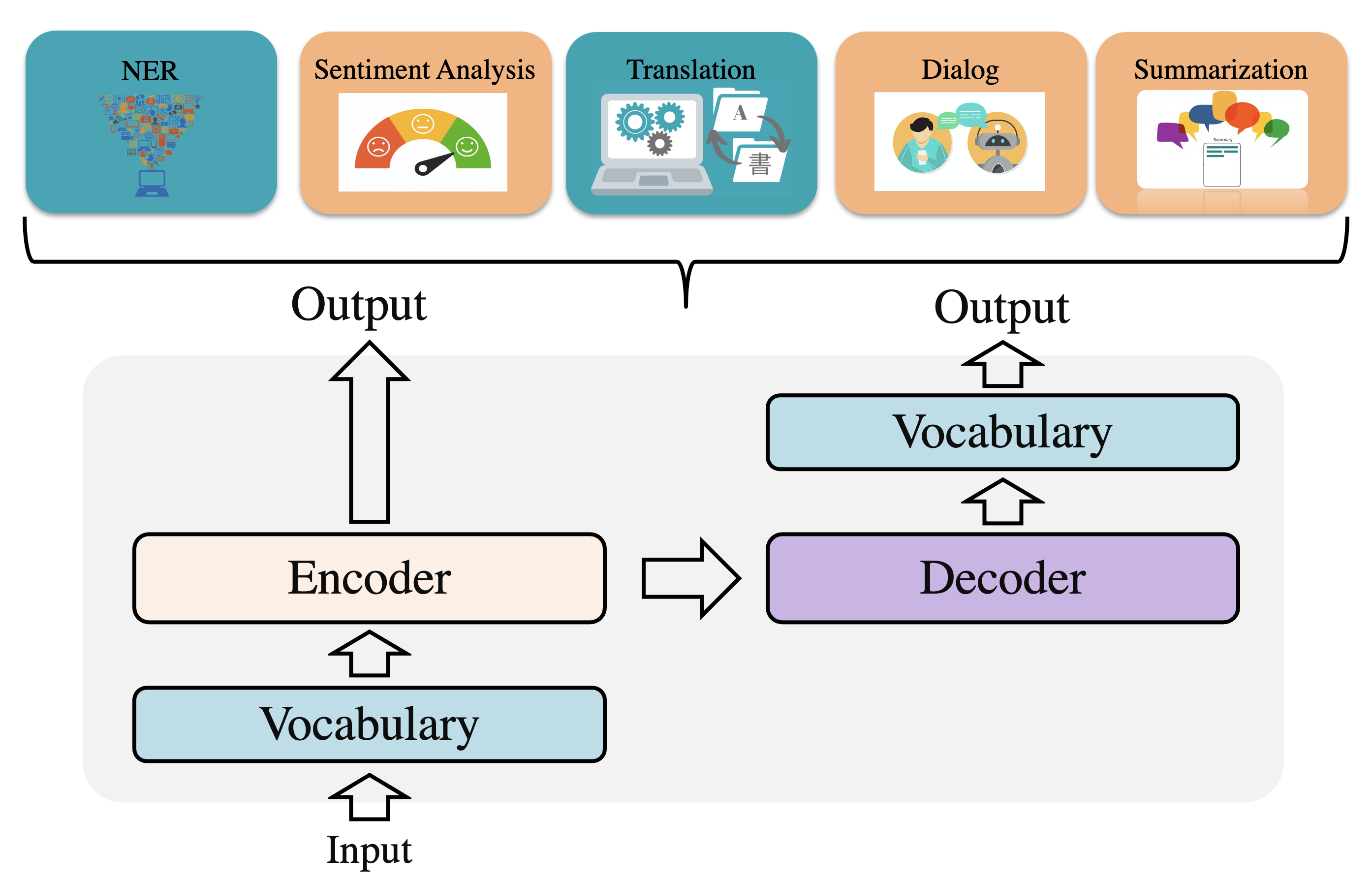
Vocabulary: The Fundamental Component
Vocabulary is a fundamental component for NLP. Due to the discreteness of text, vocabulary construction is a prerequisite for neural machine translation (NMT) and many other natural language processing (NLP) tasks using neural networks. It plays as a lookup table responsible for transferring discrete tokens into dense vectors and recovering the discrete tokens from the output distribution.
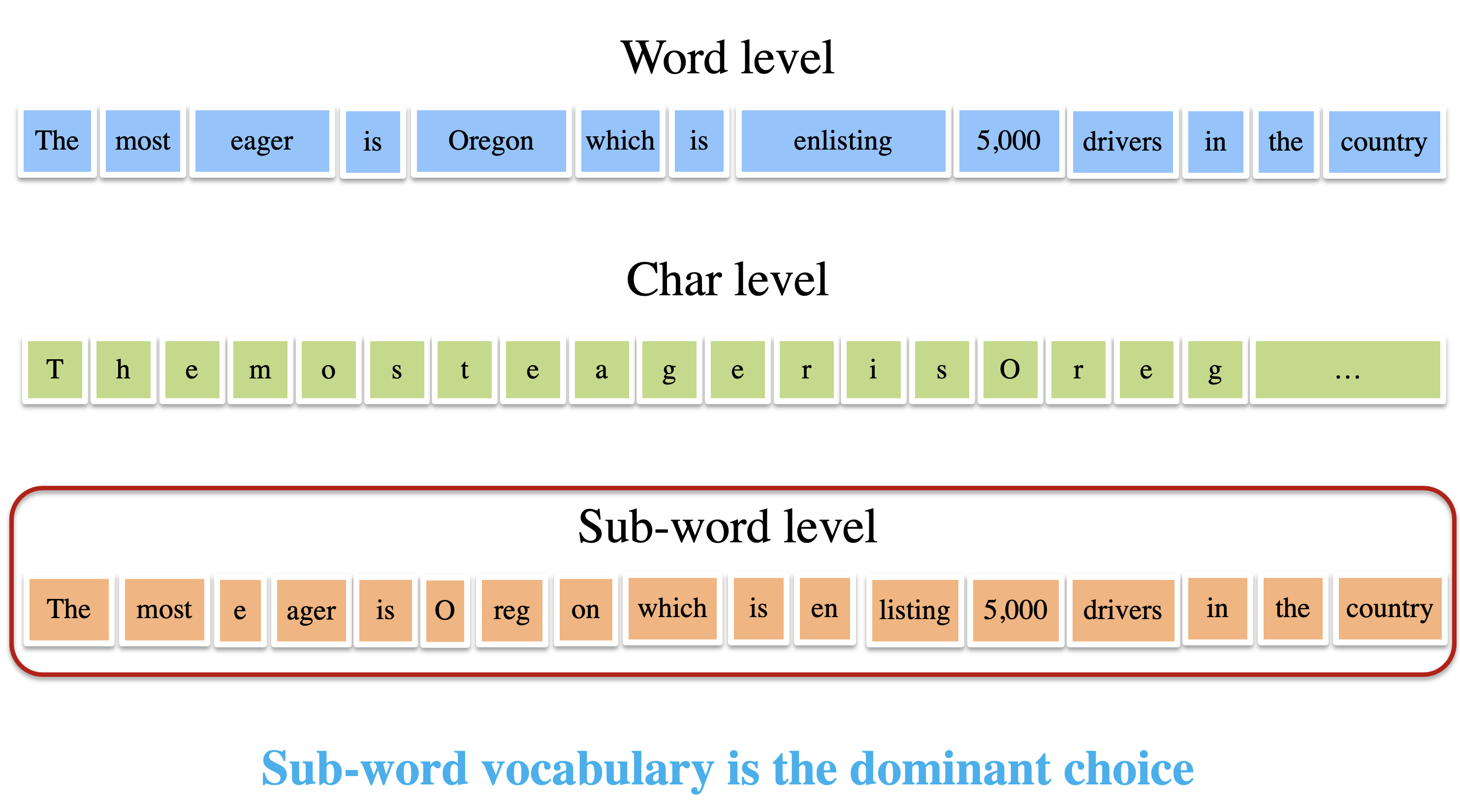
Researchers recently have proposed several advanced vocabularization approaches, like word-level approaches, byte-level approaches, character-level approaches, and sub-word approaches. Initially, most neural models were built upon word-level vocabularies. While achieving promising results, it is a common constraint that word-level vocabularies fail on handling rare words under limited vocabulary sizes. Currently, the most domainant segmentation approaches are sub-word level approaches. Byte-Pair Encoding (BPE) is the first one to get subword-level vocabularies. The general idea is to merge pairs of frequent character sequences to create sub-word units. Sub-word vocabularies can be regarded as a trade-off between character-level vocabularies and word-level vocabularies. Compared to word-level vocabularies, it can decrease the sparsity of tokens and increase the shared features between similar words, which probably have similar semantic meanings, like “happy” and “happier”. Compared to character-level vocabularies, it has shorter sentence lengths without rare words.
Despite promising results, most existing subword approaches only consider frequency (or entropy) while the effects of vocabulary size is neglected. Thus, trial training is required to find the optimal size, which brings high computation costs. In this work, we aim to figure out how to evaluate vocabularies and whether one can find the optimal vocabulary without trial training. In the next, I will introduce our work following these two questions.
How to Evaluate Vocabulary?
In this work, we mainly consider two factors to understand vocabularies: entropy and size.
Size is an essential factor. From the pespective of size, a vocabulary with smaller size is a better choice. Smaller size usually means less rare tokens and less parameters.
Entropy is also an important factor. Currently, sub-word approaches like Byte-Pair Encoding (BPE) are widely used in the community. In information theory, BPE are simple forms of data compression. The target is to reduce the entropy (or bits-per-char) of a corpus, which uses fewer bits to represent the corpus than the character-level segmentation. Therefore, entropy is a natural factor to be considered. In this work, we borrow the idea of entropy and define a concept called information-per-char (IPC for short), a normalized entropy here. We can understand IPC as semantic information per char. Less IPC means less average semantic information per character, which benefits models to differentiate these tokens and benefits for model learning. Also, compared to char-level vocabularies, BPE brings smaller IPC also with better performance. Therefore, smaller IPC is supposed to be better. Formally, IPC is calculated as
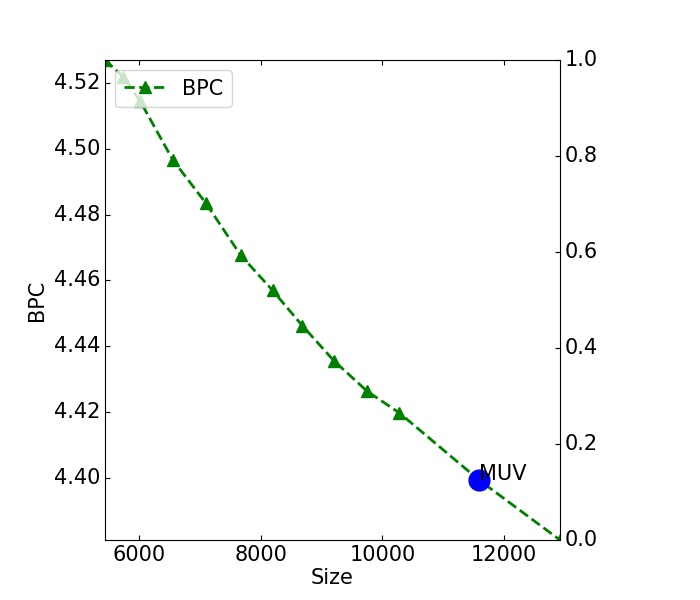
where represents a vocabulary and is the average length of . is the frequency of -th token in the training data. The following figure shows how IPC changes with the increase of vocabulary size (We take BPE as an example). We sample several figures in dir "img/".
Conflicted Factors As discussed before, IPC and size are two conflicted factors. From the perspective of size, a BPE vocabulary with smaller size is expected. From the perspective of IPC, a BPE vocabulary with larger size is expected since a BPE vocabulary with larger size usually has smaller IPC. Previous studies mainly use full training and testing on downstream tasks to select the best vocabulary. In this work, we aim to explore a more challenging problem: How to evaluate vocabulary efficiently?
MUV: The tradeoff between IPC and size. To model such a tradeoff, we borrow the concept of Marginal Utility in economics and propose to use Marginal Utility of Vocabularization(MUV) as the optimization objective.
MUV evaluates the benefits (IPC reduction) a corpus can get from an increase of cost (size). Higher MUV is expected for a higher benefit-cost ratio. Here we give an illustrative example to understand MUV.
Formally, marginal utility is defined as gradients. Here we use to approximate marginal utility:
where represents the IPC score. and are two vocabularies with length and . represents the MUV score.
On almost all languages, we find a consistent observation For BPE vocabularies. At the start, the IPC score decreases faster and faster with the increase of frequent tokens. After it reaches the point with the maximum gradients, that is marginal utility score, the speed of IPC reduction will be slower and slower. That is to say, the increase of costs does not bring too much benefits. We can stop at the point with the maximum marginal uitilty. It is the most straightforward approximation. Since we can still get positive benefits from the increase of costs, it is ok to define a better formulation if more costs are tolerable. For convenience, we use the cost-effective point as the optimal one.
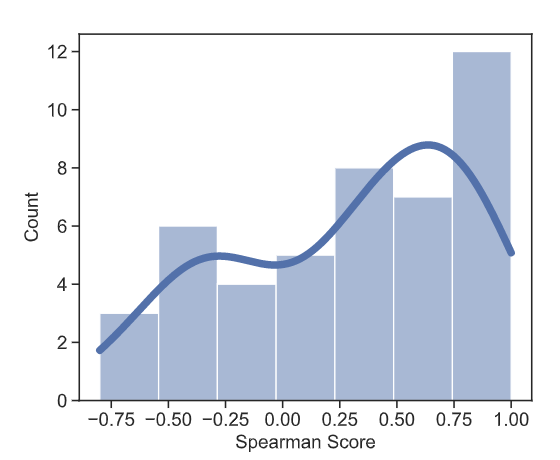
Results. To verify the effectiveness of MUV as the vocabulary measurement, we conduct experiments on 45 language pairs from TED and calculate the Spearman correlation score between MUV and BLEU scores. We adopt the same and widely-used settings to avoid the effects of other attributes on BLEU scores, such as model hyper-parameters and training hyper-parameters. We generate a sequence of vocabularies with incremental sizes via BPE. All experiments use the same hyper-parameters. Two-thirds of pairs show positive correlations. The middle Spearman score is 0.4. Please refer to our paper for more dataset details. We note that the spearman score is not very high for some datasets. Actually, many factors can affect BLEU scores. It is hard to get solid correlation scores between BLEU and any factors. Therefore, we believe that such correlation scores are acceptable for these complicated relations.
How to Find the Optimal Vocabulary?
Given MUV, we have two natural choices to get the final vocabulary: search and learning. In the search-based direction, we can combine MUV with widely-used vocabularization solutions (MUV-Search for short). For example, the optimal vocabularies can be obtained by enumerating all candidate vocabularies generated by BPE. It is a simple and effective approach. According to our results, we recommend this solution because it can search for a better vocabulary than widely-used vocabulary. However, despite the simplicity, this approach requires a lot of time to generate vocabularies and calculate MUV. To address these problems, we further explore a more general solution, VOLT, to explore more vocabulary possibilities.
Problem Definition
Given MUV scores, the problem of searching for the optimal vocabulary can be transferred to the problem of searching for the vocabulary with the maximum MUV scores.

However, the main challenge is the discrete and huge vocabulary space. Strictly speaking, we need to enumerate all vocabulary sizes. This paper simplifies this problem by searching for the optimal vocabulary from vocabularies with fixed sizes.
We introduce an auxiliary variable ( is an incremental integer sequence) to define these fixed sizes. Formally, where each timestep represents a set of vocabularies with the length up to . is the interval size. (Here is "up to", rather than "equal to").
That is to say, we only need to enumerate all vocabularies with sizes defined by sequence . For a vocabulary with size , its MUV score also relies on a smaller vocabulary. For simplification, we adopt the vocabulary from vocabularies with size to calculate the MUV socres for vocabularies with size . The problem can be formulated as:
where and represent vocabulary sets with size and , respectively. is the function to calculate IPC score. We use to estimate the size gap between two vocabularies and .
An Intuitive Understanding. The inner represents that the target is to find the vocabulary from with the maximum MUV scores. The outer means that the target is to enumerate all timesteps and find the vocabulary with the maximum MUV scores.
Additional Notes For a valid , the size of is required to be smaller than . Actually, in our formulation the size of may be larger than . Therefore, the search space contains illegal paris (, ). Actually, following our IPC curves, we can find that smaller vocabulary usually have large . According to these findings, we can assume the following holds:
Therefore, these illegal pair does not affect our results.
Problem Re-formulation
The target problem is a discrete optimization problem. We propose formulating it into a widely-studied discrete optimization problem, optimal transport, and then adopting the advanced solutions to optimize our problem.
The re-formulation is a little bit of complicated. We start from the upper bound of the target problem (Eq.1):
Why is this objective the upper bound? If we ignore the outer and only consider the inner , we can get the following re-formulation:
where the is a constant that does not affect the optimization, which can be ignored. We can further re-formulate the target into:
and we can get the upper bound is:
Why do we start from the upper bound? The motivation is pretty simple somehow. It is because we want to transfer the target into the entropy-based optimal transport formulation. The original target usually contains . In this way, we only need to calculate the maximum entropy given each timestep.
Solution
Given the upper bound, the only thing we need to do is to find a vocabulary from with the maximum entropy score. Then, we can enumerate all timesteps to find the best one satisfying the upper bound of the target. Formally, we re-write the target into
where is the frequency of token in the vocabulary . represents the length of token . Notice that both the distribution and the average length depend on the choice of .
For simplification, we start from a BPE vocabulary containing top most frequent tokens. Formally, let be the vocabulary containing top most frequent tokens, be the set of chars and be their sizes respectively. The following inequation holds:
Why does this inequation hold? The left term is the minimum negative entropy value for all vocabulary candidates. The right term is the negative entropy value for a specific vocabulary. Of course, the left term is less than the right term.
How do we solve this optimization problem? We start from the upper bound of the above objective function, that is and then search for a refined token set from . In this way, we reduce the search space into the subsets of . Let be the joint probability distribution of the tokens and chars that we want to learn where means the -th character and means the -th token candidate. Then we have
where is the sebset of . The second term is exactly equal to zero for a valid P. If the character in the token , . If the character not in the token , . The second item is always set to be zero.
Why do we add the second term? It is used to match the target of optimal transport. You can follow the next section for more details.
Since is nothing but the negative entropy of the joint probability distribution , we shall denote it as . Let be the matrix whose -th entry is given by , and let be the joint probability matrix, then we can write
Here we transport the problem into the optimal transport target
Setup of OT From the perspective of optimal transport, can be regarded as the transport matrix, and can be regarded as the distance matrix. Intuitively, optimal transport is about finding the best transporting mass from the char distribution to the target token distribution with the minimum work defined by . actually is the matrix. First, we set the distance to if the target token does not contain the char . Otherwise, we use to estimate where is the length of token .
Furthermore, the number of chars is fixed, and we set the sum of each row in the transport matrix to the probability of char . The upper bound of the char requirements for each token is fixed, and we set the sum of each column in the transport matrix to the probability of token .
Formally, the constraints are defined as:
Implementation
At each timestep, we can get the vocabulary with the maximum entropy based on the transport matrix. It is inevitable to handle illegal transport cases due to relaxed constraints. We remove tokens with distributed chars less than token frequencies. Finally, we enumerate all timesteps and select the vocabulary satisfying Eq.1 as the final vocabulary. The following figure shows the details of VOLT.

The inputs to VOLT contain training data, token candidates in training data, character sets, an incremental integer sequence . In this work, we use the tokens generated by BPE for initialization. Of course, you can use other approaches to get token candidates.
We use the Sinkhorn algorithm in implementation. The algorithm defines two parameters: and . We just used the standard solution. You can refer to Optimal Transport for algorithm details.
Finally, we enumerate all sizes in to calculate the maximum entropy and associated with vocabulary. The vocabulary satisfying the upper bound of the target is the final choice.
Results
We compare VOLT with popular vocabularies. For bilingual translation, we use BPE-30K as the popular vocabulary choice. For multilingual, we use BPE-60K as the popular vocabulary choice. In this blog, I post some main results. You can refer to the full paper for more results.
Bilingual Translation
We conduct experiments on WMT En-De translation, TED bilingual translation. As we can see, the vocabularies searched by VOLT achieve higher or competitive BLEU scores with large size reduction. The promising results demonstrate that VOLT is a practical approach that can find a well-performing vocabulary with higher BLEU and smaller size.
Multilingual Translation
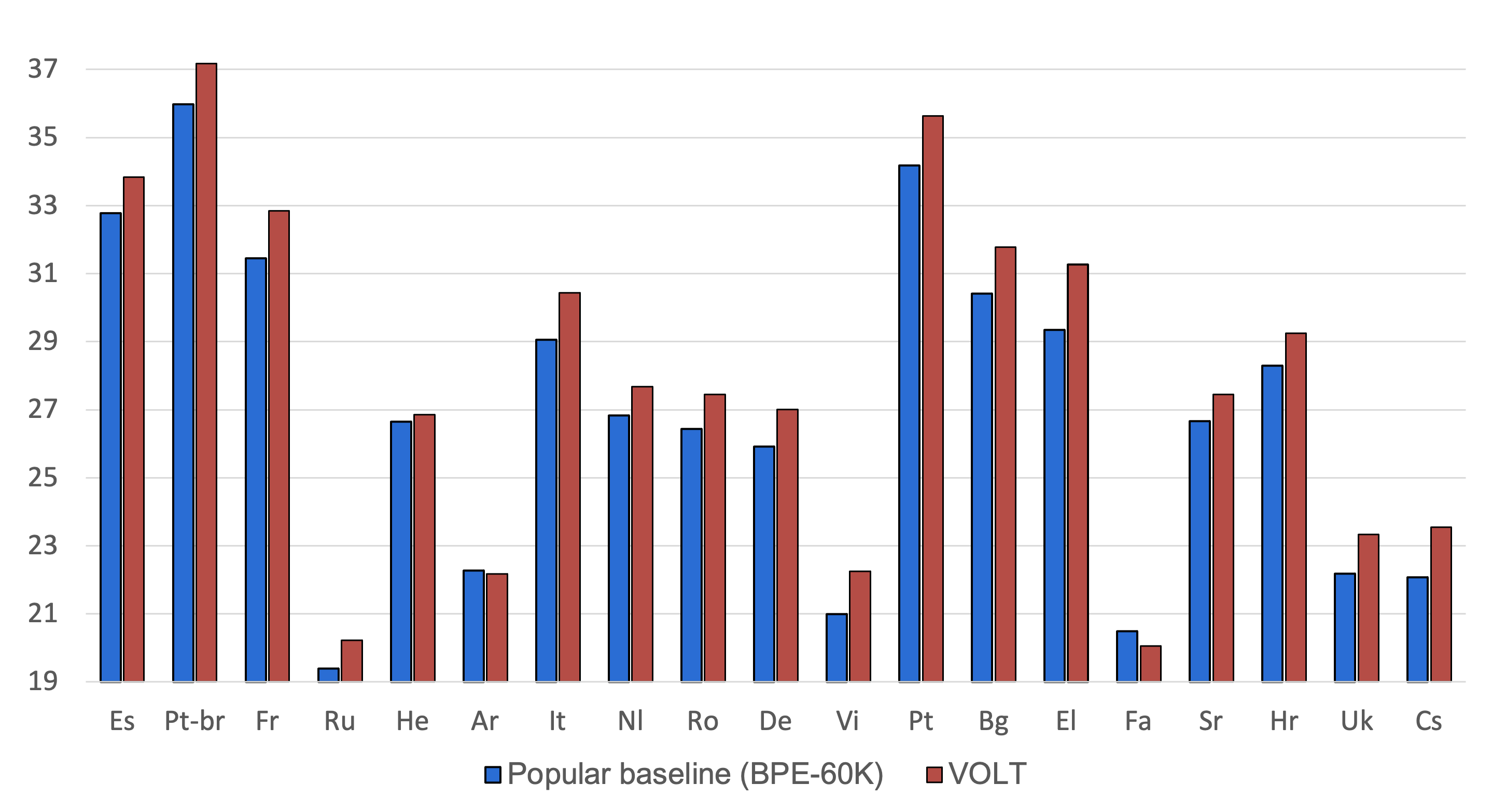
We also conduct experiments on multilingual translation. These languages come from multiple language families and have diverse characters. The size of the searched vocabulary is around 110K. As we can see, VOLT achieves better BLEU scores on most pairs.
Search Time
One advantage of VOLT lies in its low resource consumption. We first compare VOLT with BPE-Search, a method to select the best one from a BPE-generated vocabulary set based on their BLEU scores. In BPE-Search, we first define a vocabulary set including BPE-1K, BPE-2K, BPE-3K, BPE-4K, BPE-5K, BPE-6K, BPE-7K, BPE-8K, BPE-9K, BPE-10K, BPE-20K, BPE-30K. Then, we run full experiments to select the best vocabulary. The cost of BPE-Search is the sum of the training time on all vocabularies. VOLT is a lightweight solution that can find a competitive vocabulary with much less computation requirements.

Codes and Datasets
We have uploaded our codes into VOLT. You can use one line of commands to try VOLT.